(If you want to cut to the chase, skip the first four paragraphs.)
Over the past year, Amazon Web Services (AWS) has previewed and released several new services that have the potential to drive the cost of IT down. This includes services like EFS and Aurora, but the service I was most excited about was Lambda. Lambda is a service that executes code on-demand so you don’t have to pay for an entire EC2 instance to sit around waiting for events. I recall at my previous position having a server that only existed to execute scheduled tasks. As supported languages expand, Lambda has the potential to completely replace such utility servers.
There are many ways to trigger Lambda functions, including S3 events, SNS messages and schedules. But, until recently, it wasn’t straightforward to trigger a Lambda event from outside your AWS environment. Enter Amazon’s fairly new API Gateway. The API Gateway is a super simple way to setup http endpoints that communicate with AWS resources, including Lambda functions. And, you don’t have to be a seasoned developer to use it. In fact, I had only recently started learning some standard concepts while playing around with the Slim Framework for PHP. While understanding RESTful APIs will help the API Gateway feel more natural, you can get started without knowing everything.
Let me back up a bit and explain why I came across the API Gateway in the first place. SendGrid has become our go-to service for sending email from various applications. I can’t say enough good about SendGrid, but it has some intentional limitations. One of those is that it will store no more than 500 events or 7 days (whichever comes first) at a time. You still get all your stats, but if you need to look up what happened to a specific email two weeks ago (or two minutes ago depending on your volume), you’re out of luck. Fortunately, SendGrid thought this through and made an event webhook available that will POST these events as a JSON object to any URL you give it. “Perfect!” I thought, “We can build something to store it in RDS.” But first, I thought it prudent to explore the Internet for pre-built solutions.
My research brought me to Keen.io, which was the only out-of-the-box solution I found that would readily accept and store SendGrid events. If you are here for the exact same solution that I was looking for, I strong recommend checking out Keen.io. The interface is a little slow, but the features and price are right. We would have gone this route in a heartbeat, but had some requirements that the terms of service could not satisfy. With that option gone, I was back to the drawing board. After brainstorming many times with my teammates, we finally came up with a simple solution: SendGrid would POST to an http endpoint via the API Gateway, which would in turn fire up a Lambda function, which would take the JSON event and write it to an S3 bucket. The reason for S3 instead of something more structured like RDS or SimpleDB is because we can use Splunk to ingest S3 contents. Your requirements may be different, so be sure to check out other storage options like those I have mentioned already.
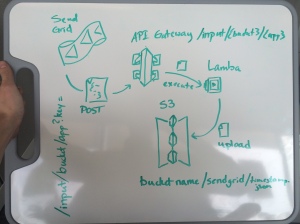
The initial plan. The API structure changed, but the flow of events is still accurate.
Now that we have introductions out of the way, let’s jump in and start building this thing. You will need to be familiar with creating Lambda functions and general S3 storage management. Note that I will borrow heavily from the API Gateway Getting Started guide and Lambda with S3 tutorial. Most of my testing took place on my personal AWS account and cost me $.02.
Create an S3 Bucket
The first thing you need to do is create your S3 bucket or folder that will store SendGrid events as files (you can also use an existing bucket). The simple GUI way is to open your AWS console and access the S3 dashboard. From there, click the Create Bucket button. Give your bucket a unique name, choose a region and click Create.
Create a Lambda Function
This won’t be an in-depth guide into creating Lambda functions, but we will cover what you need to know in order to get this up and running. At the time of writing, Lambda supports three languages: Java, Node.js, and Python. I will use Node.js in this guide.
The Code
Create a file called index.js and add the following contents:
//Modified from AWS example: http://docs.aws.amazon.com/lambda/latest/dg/with-s3.html
var AWS = require('aws-sdk');
exports.handler = function(event, context) {
console.log("routeToS3 Lambda function invoked");
//Restrict this function so that not just anyone can invoke it.
var validToken = event.validToken;
//Check supplied token and kill the process if it is incorrect
var token = event.token;
if (token != validToken) {
console.log('routeToS3: The token supplied (' + token + ') is invalid. Aborting.');
context.fail('{ "result" : "fail", "reason" : "Invalid token provided" }');
} else {
uploadBody(event, context);
}
};
uploadBody = function(event, context) {
var bucket = event.bucket;
var app = event.app;
var timestamp = Date.now();
var key = app + '_' + timestamp;
var body = JSON.stringify(event.body);
var s3 = new AWS.S3();
var param = {Bucket: bucket, Key: key, Body: body};
console.log("routeToS3: Uploading body to S3 - " + bucket);
s3.upload(param, function(err, data) {
if (err) {
console.log(err, err.stack);// an error occurred, log to CloudWatch
context.fail('{ "result" : "fail", "reason" : "Unable to upload file to S3" }');
} else {
console.log('routeToS3: Body uploaded to S3 successfully');// successful response
context.succeed('{ "result" : "success" }');
}
});
};
This script will become your Lambda function and has a few key elements to take note of. First, it declares a variable named AWS with “require(‘aws-sdk’)”. This pulls in the aws-sdk Node.js module, which is required for writing to S3. With most Node.js modules, you will need to zip up the module files with your Lambda function. However, the AWS SDK is baked in, so you don’t need to worry about uploading any dependency files with the above function.
Next, the function declares a series of variables, starting with “validToken” and “token.” This might be where most seasoned API engineers roll their eyes at me. When possible, it makes sense to handle authentication at the API level and not inside your function. In fact, the API Gateway has this functionality built in. However, the supported method requires a change to the incoming requests header. That is not an option with SendGrid’s event webhook, which only gives you control over the URL, not the data. So, I had to cheat a little. We will cover this a little more when we setup the API, but for now it is sufficient to understand that token must match validToken for the function to work. Otherwise, the function will exit with an error.
Moving on to the other important variables:
- bucket – The bucket or bucket/path combination (e.g.: my-bucket/SendGridEvents)
- app – The name of the app these events are coming from; will be used as the resulting file’s prefix
- timestamp – The current timestamp, which will be used to make the file name/key unique
- key – constructed from app and timestamp to generate the file name
All of these variables will be passed in via the API Gateway as part of the event variable. That is why they all look something like “bucket = event.bucket”.
When this script is run, the very first thing Lambda will do is call the “exports.handler” function. In our case, exports.handler simply checks the token and, if it is correct, calls the “uploadBody” function. Otherwise, it exits the script and writes an error to CloudWatch via console.log.
Zip up index.js and use it to create a new Lambda function named “routeToS3.” You can do this all through the GUI, but I am more familiar with the CLI method. Not because I am a CLI snob, but because when Lambda first came out, only account admins could access the Lambda GUI.
Create your API
The AWS API Gateway enables people to build APIs without typing a line of code. It’s really fast to get something up and running. In fact, when all I meant to do was make sure my permissions were set correctly, I accidentally built the whole thing. I recommend checking out AWS’s guide, but you can also learn a bit by following along here.
To start…
- Log into your AWS console and open up the API Gateway service and click the Create API button.
- Name your API routeToS3 and click the next Create API button.
- With the root resource selected (it should be your only resource at this point), click Actions -> Create Resource.
- Name the resource “input” and set the path to “input” as well.
- Select /input from Resources menu on the left.
- Click Actions -> Create Method.
- In the dropdown that appears on the Resources menu, select POST and click the checkmark that appears to the right.
- For Integration Type, choose Lambda Function.
- Set your Lambda Region (choose the same region as your S3 bucket).
- Type or select the name of your Lambda function (routeToS3) in the Lambda Function field.
- Click Save
- When prompted to Add Permission to Lambda Function, click OK.
Congratulations! You just built an API in about two minutes. Now, in order to make sure the Lambda function gets all the parameters we mentioned earlier (body, bucket, app, etc.), we need to configure query strings, a mapping template, and a stage variable. We won’t be able to create a stage variable just yet, so that will come a little later.
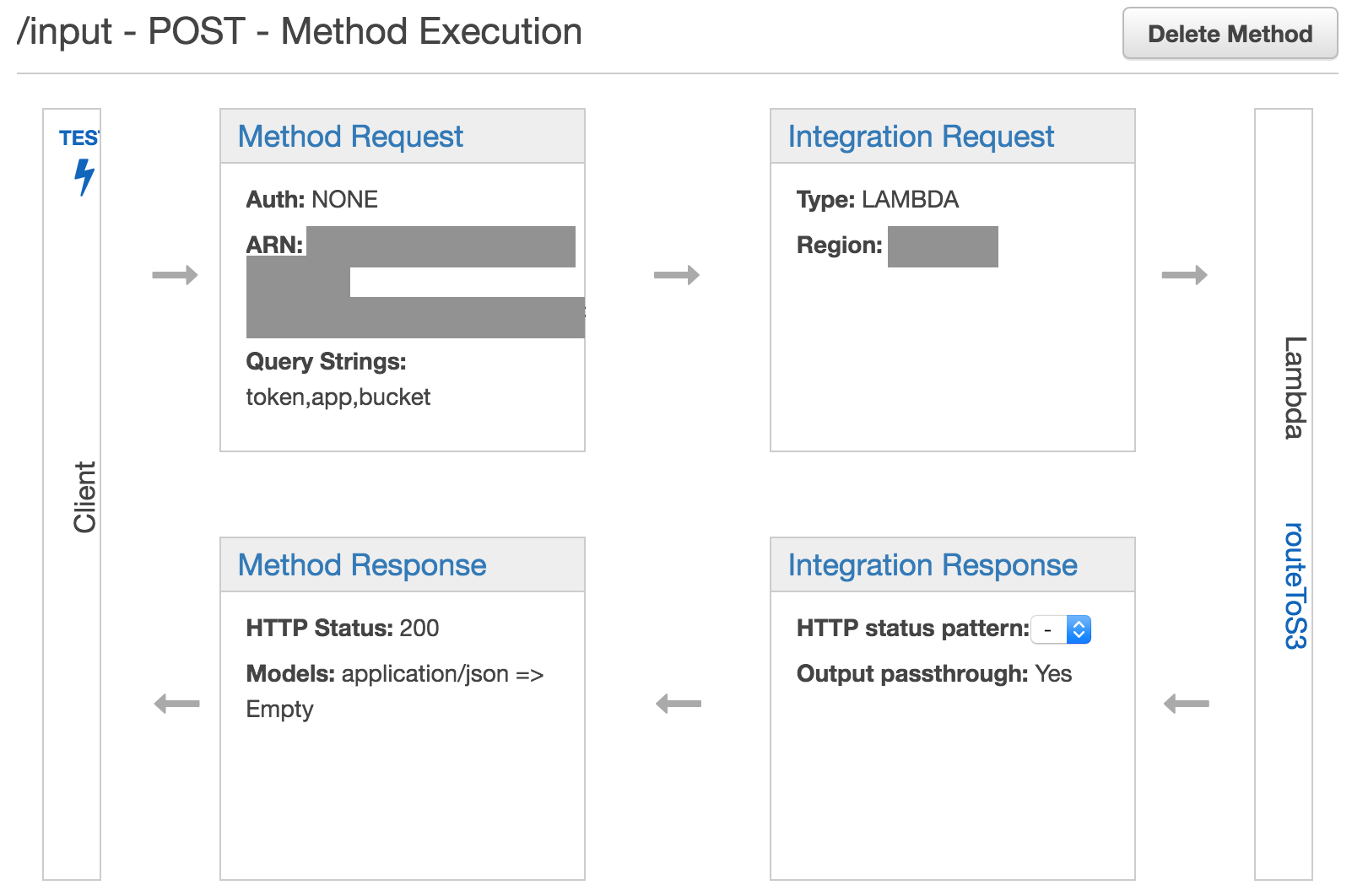
With your POST method selected in the Resources menu, you should see a diagram with boxes titled Method Request, Integration Request, Method Response, and Integration Response:
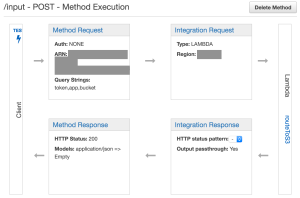
Click on Method Request to setup our query strings. From here, click to expand the URL Query String Parameters section. Any query string we add here will act as what some of us might refer to as GET parameters (e.g.: /?var1=a&var2=b&var3=etc). To setup the strings we will need, follow these steps:
- Click the Add query string link.
- Name the string token and click the checkmark to the right.
- Repeat for app and bucket.
Go back to the method execution overview by clicking POST in the Resources menu or <- Method Execution at the top.
Next, we will add a mapping template:
- Click Integration Request.
- Expand the Body Mapping Templates section.
- Click Add mapping template
- Type application/json (even though it is already filled in and doesn’t disappear when you click inside the text box) and click the checkmark to the right.
- Click the pencil icon next to Input Passthrough (it’s possible you could see “Mapping template” instead).
- Add the following JSON object and click the checkmark
{
"bucket": "$input.params('bucket')",
"app": "$input.params('app')",
"token": "$input.params('token')",
"validToken": "$stageVariables.validToken",
"body": $input.json('$')
}
This mapping will take the body of the request and our variables, and pass them along as part of the event object to Lambda. Note that all values, like “$input.params(‘bucket’)” are wrapped in double quotes, except for $input.json(‘$’). That is because we are actually calling a function on the body (‘$’), so wrapping it in quotes will break things.
Now, it’s time to deploy our API, which will make it accessible over HTTP. But, we haven’t tested it yet and that validToken variable is still undefined. Don’t worry, we haven’t forgotten those two critical pieces. But, we have to create a stage first, which is part of the deployment process.
- Click the Deploy API button at the top of the screen.
- On the screen that appears, choose [New Stage] for the Deployment Stage.
- Choose a name for the stage (Stages are like different environments, for example dev or prod).
- Enter a Deployment description and click Deploy.
On the screen that follows, you will see a tab labeled Stage Variables. Open this tab and click Add Stage Variable. Name the variable validToken and enter a token of your choosing for the Value. Use something strong.
Go back to the Settings tab and take a look at the options there. You may be interested in throttling your API, especially if this is a development stage. Remember that, although the API Gateway and Lambda are fairly cheap, too much traffic could rack up a bill. Since we aren’t using a client certificate to authenticate the calling app, we have to invoke the Lambda function to verify the provided token. Just something to keep in mind when considering throttling your API.
Now that I’ve distracted you with some prose, click Save Settings at the bottom of the page.
At the top of the screen, you will see an Invoke URL. This is the address to access the stage you just deployed into. All of our magic happens in the /input resource, so whatever that invoke URL is add “/input” to the end of it. For example, https://yudfhjky.execute-api.region.amazonaws.com/dev would become https://yudfhjky.execute-api.region.amazonaws.com/dev/input.
With our stage setup, we can now test the method.
- Go back to the routeToS3 API and click on the POST method in the Resources menu.
- Click Test.
- Enter a token, app, and a valid bucket/folder path (e.g.: my-bucket/routeToS3/SendGrid)
- Enter a value for validToken (this should be the same as token if you want the test to succeed).
- For Request Body, type something like {“message”: “success”}.
- Click Test.
You should see the CloudWatch logs that indicate the results of your test. If all is well, you will get a 200 status back and a corresponding file will appear the bucket you provided. The file contents should be {“message”: “success”} or whatever you set for the request body.
If things are working as expected, then it is time to head over to SendGrid and configure your event webhook:
- Log into SendGrid.
- Click Settings -> Mail Settings.
- Find Event Notification.
- Click the gray Off button to turn event notifications on.
- If needed, click edit to enter the HTTP POST URL.
- Enter the URL to your API endpoint, along with all necessary query strings (e.g.: https://yudfhjky.execute-api.region.amazonaws.com/dev/input?bucket=my-bucket/routeToS3/SendGrid&token=1234567890&app=SendGrid).
- Click the checkmark.
- Check all the events you want to log.
- Click the Test Your Integration button.
- Wait a couple minutes and then check your bucket to see if SendGrid’s test events arrived.
Tada! You should now be logging SendGrid events to an S3 bucket. Honestly, it’s much simpler than you might think based on the length of this post. Just keep the perspective that all of this is accomplished with three lightweight and low-cost services: the API Gateway to receive the event from SendGrid, Lambda to process that event and upload it to S3, and S3 to store the body of the SendGrid event. I hope you find this as helpful and straightforward as I have.




{kind=link}
{kind=link}